你还在为孩子一次考试少考了5分失眠吗?——别傻了,现在学校评价那套早就变了。他们嘴上还说着“期末成绩”,但手里捏着的,其实是另一本账:孩子进步了多少。对,就是那个听起来有点学术的词——增值性评价。
说实话,我第一次听到这个说法,也觉得不就是看进步嘛,有什么新鲜的。但后来跟几个校长聊完,才发现,这事儿远不是“比上次多考10分”这么简单。它几乎在重塑我们看孩子的眼光。
问:增值性评价,说的不就是“看进步”吗?这有什么复杂的?
答:如果只是这么理解,你可小看它了。传统评价像拍一张照片——咔嚓,定格你此刻的位置。增值评价更像一部延时摄影,它关注的不是单次分数,而是学生在一段时间内,相对于起点,到底前进了多远。而且最关键的是,它要剥离掉家庭背景、先天智商这些孩子没法控制的因素。举个例子:一个农村孩子从60分考到75分,和城里孩子一直保持95分,谁“增值”更多?这套算法会告诉你,前者的教育贡献可能更大。❗
一、到底什么是增值性评价?
我第一次听到的时候,差点被一堆统计术语劝退。什么“多层线性模型”、“残差值”…得,这些你别管。你只需要明白:它回答了一个扎心的问题——学校到底把孩子教好了,还是本来生源就好?
过去我们评价一所学校,就看升学率、平均分。但你想过没,重点校掐尖招生,学生进来时就几乎满分,三年后还是高分,这能说明学校“会教”吗?增值评价就是要把这些水分挤掉。它用入学时的基线数据,预测每个孩子可能达到的水平,然后看期末时是否超出了预期。超出了,就是正增值;没达到,哪怕分数挺高,也算负增值。
问:可我家孩子每次考试都比上次好,这不就是增值了?
答:问题就在于“每次都比上次好”可能是个幻觉。你细想,试卷难度不一样吧?心情状态不一样吧?单纯比较原始分,波动太正常了。增值评价厉害的地方在于,它用复杂的统计方法,把影响成绩的外部因素尽量过滤掉,只看“净增”的部分。比如,它会考虑学生的家庭经济状况、父母学历,甚至班级整体的起点。这样一来,评价就相对公平了——至少,它让那些生源一般的学校扬眉吐气:看,我们才是真的把普通孩子教出息了!💡
二、为什么一夜之间所有学校都在谈这个?
政策大风向是一回事,但真正推着学校跑的,是那该死的比较——而且这种比较终于有人替他们喊冤了。
几年前我去一所城郊结合部初中采访,校长满脸无奈:“我们招进来的学生,小学基础平均比市区校差一大截,三年后中考平均分还是差,但教育局考核时谁管你起点啊?”现在不一样了。教育部近几年文件连续点名“改进结果评价,强化过程评价,探索增值评价”,简直点到了基层的痛点上。更关键的是,很多地方已经开始试点,用增值数据去配置资源、评优评先。你不搞?那好,经费、荣誉慢慢就跟你没关系了。
不过话又说回来——有些家长听到这儿已经急了:“那是不是以后不公布排名了?不竞赛了?”啧,这是最容易被误解的地方。
问:那是不是意味着分数不重要了?
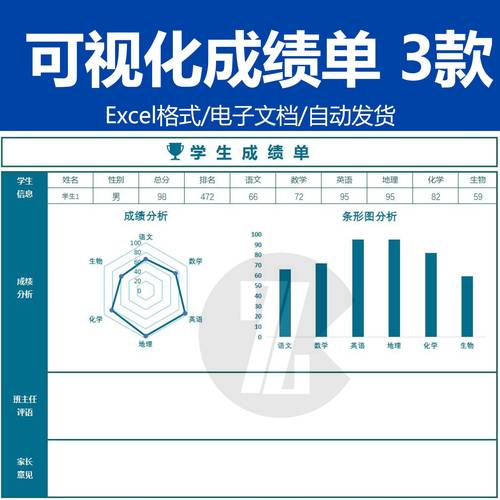
答:重要,但不再是唯一的命根。打个比方:分数是你的身高数据,增值评价是你的生长速度。一个1.8米的人如果一年没长,远比一个1.5米但窜到1.6米的人“生长价值”低。所以,考试分数还是那个分数,但解读方式变了。学校也不会只拿一张成绩单来给你开家长会了,他们手里还有一份你看不到的“增值报告”,上面可能写着:您孩子数学虽然只有78分,但基于入学水平和背景因素,他已经超预期发挥12%,位列年级增值前10%!这不比单纯78分更能说明问题?
三、增值评价落地有多难?
说得好听,但你以为学校真能轻松搞定?天真!我亲眼见过凌晨两点,老师们还在往系统里补录行为表现数据、品德发展观测点……那叫一个崩溃。❗
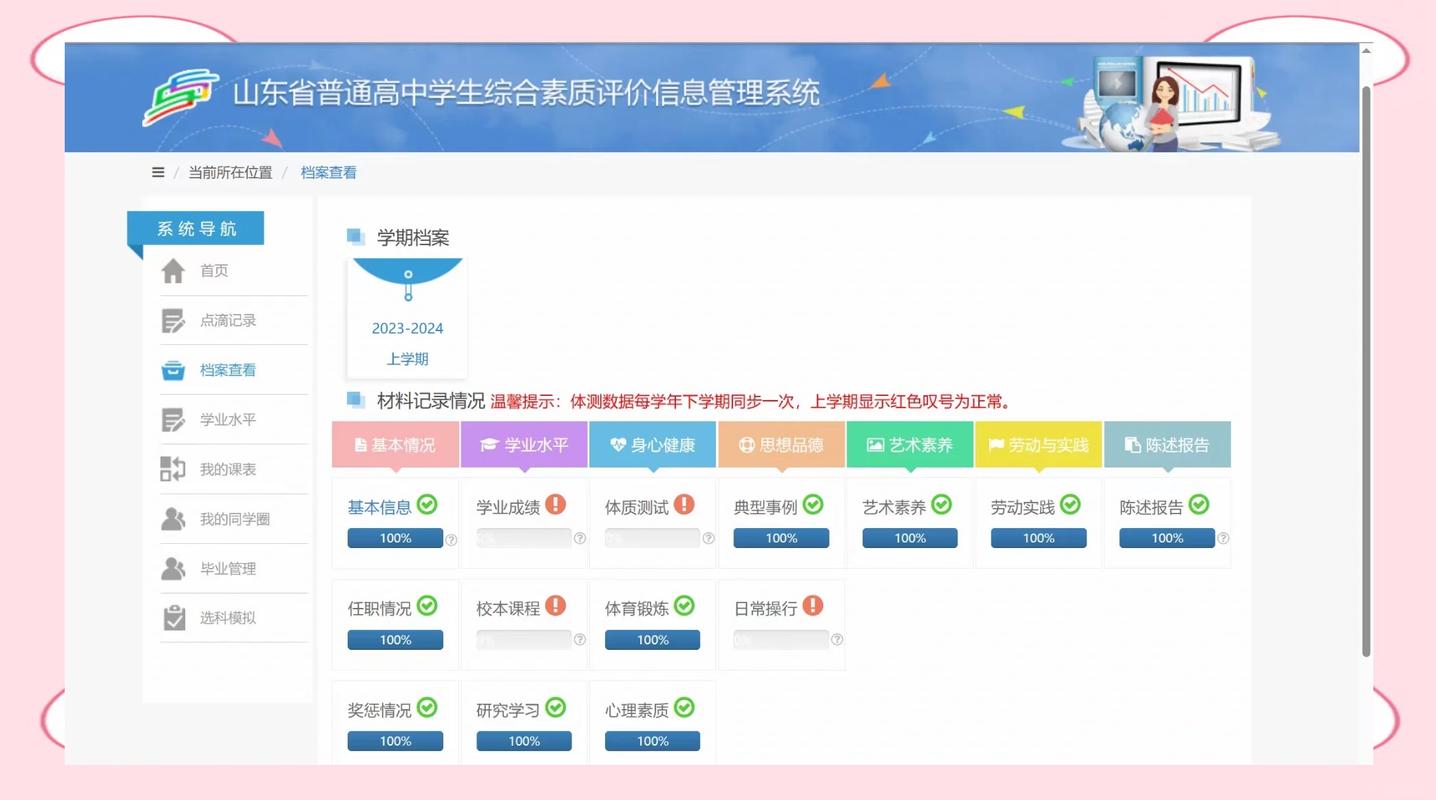
技术平台五花八门,数据采集要求越来越细:不仅要学科成绩,还要有课堂参与度、合作能力、创新思维……很多老师跟我吐槽:“我们快成记录员了,备课时间被挤占得厉害。”而且,统计模型选哪家?是用的学生成长百分等级模型,还是多层线性模型?不同模型算出来的增值结果能差出一个档次,直接影响学校排名。这背后,又是一堆技术公司的生意。
更让人恼火的是——有些地方搞着搞着就变味了。本来是为了改进教学,结果成了考核教师的KPI,老师压力大到开始“投数据所好”,专抓容易出增值的点,教育又变成了另一种应试。
四、我为什么还是对它又爱又恨?
恨的是,它可能成为新的标签机器。“哦,这个孩子是负增值的”,你听听,这像不像又一种歧视?爱的是,它终于能让那些默默耕耘、收着“普通苗”却育出“进步果”的老师和学校,被看见。
我们太需要一种评价,去对抗那种“唯起点论”——你出身好、学校好,你永远赢;出身差、资源少,你再拼命也像小丑。增值评价撕开了一道口子:教育的价值,不是挑选胜利者,而是创造胜利者。

但我也怕。怕它被简化成冰冷的排名工具,怕家长又一窝蜂追逐“增值率”而逼孩子。所以,下次开家长会,如果老师跟你聊起增值评价,别急着问“我家孩子增值排第几”,多问一句:“老师,您觉得他在哪些方面真的变好了?”——那个答案,可能比任何一个模型都接近真相。
毕竟,人不是数据点,对吧?